Инструкция для пользователей Общественно-политического подкорпуса
Составитель: А.М. Галиева
Казань - 2017
1. О подкорпусе
Общественно-политический подкорпус (подкорпус общественно-политических текстов) татарского языка является тематическим лингвистическим ресурсом современного татарского языка. Проект выполняется в Институте прикладной семиотики Академии наук Республики Татарстан в рамках гранта Российского научного фонда «Разработка моделей связывания терминологии в разных языках (на материале русского и татарского языков)», проект № 16-18-02074.
Общественно-политическая область – это широкая область современных общественных отношений, знания о которой входят в компетенцию образованных людей-неспециалистов. Данная область охватывает следующие основные сферы:
- политику и сферу управления,
- международные отношения,
- экономику и финансы,
- производство и промышленность,
- армию и военные отношения,
- социальную сферу,
- культуру и искусство,
- религию,
- спорт и др.
Наибольшее проявление общественно-политическая область находит в публикациях средств массовой информации общей направленности, которые включают в обсуждение материал большого количества конкретных предметных областей, содержат большое количество терминов, и при этом адресованы непрофессионалам и понятны непрофессионалам. Общественно-политическая сфера — одна из наиболее динамично развивающихся сфер современной жизни, соответственно, общественно-политическая лексика находится в непрерывном развитии и постоянно обогащается новыми языковыми единицами, отражающими реалии современной жизни. Поэтому материалы общественно-политического подкорпуса имеют большое значение для всестороннего и объективного исследования процессов, происходящих в современном татарском языке.
Объем подкорпуса на декабрь 2016 года составляет более 10 миллионов словоупотреблений. В качестве основных источников были использованы тексты официальных документов, размещенные на портале «Официальный Татарстан», материалы СМИ, учебников по общественным наукам на татарском языке и др.
Тексты, включенные в подкорпус, снабжены морфологической разметкой (представлена информация о части речи и грамматических характеристиках словоформы). Морфологическая разметка текстов выполняется автоматически с использованием модуля двухуровневого морфологического анализа татарского языка, реализованного в программном инструментарии HFST (Helsinki Finite-State Transducer Technology).
Поисковая система подкорпуса позволяет искать материал по лексеме, словоформе, а также по отдельным грамматическим характеристикам.
Разрабатываемый подкорпус адресован широкому кругу пользователей: лингвистам, специалистам в области татарского и тюркского языкознания, преподавателям татарского языка, деятелям культуры; материалы подкорпуса отражают актуальные тенденции в использовании татарской общественно-политической терминологии и могут оказать неоценимую помощь журналистам, переводчикам, общественным деятелям, а также всем, кто изучает и интересуется татарским языком.
2. Система грамматической аннотации подкорпуса
Существенной особенностью лингвистических корпусов является система разметки, от характера и степени разработанности которой во многом зависят возможности, предоставляемые для пользователя.
Система морфологической разметки общественно-политического подкорпуса татарского языка основана на системе грамматической аннотации Татарского национального корпуса "Туган тел" и нацелена на представление всех реально существующих грамматических форм слов, не всегда отражаемых в описательных исследованиях по татарской грамматике, либо имеющих различные альтернативные трактовки [Галиева, Хакимов, Гатиатуллин 2013].
Для формального представления татарской агглютинативной морфологии используется модель, в которой словоформа строится на основе последовательного присоединения к основе регулярных словообразовательных и словоизменительных аффиксов. Например, имя существительное имеет следующую регулярную структуру: <основа> <множественность> <притяжательность> <падежность> <модальность> (китап-лар-ы-нда-мы, бала-лар-ыгыз-га-дыр).
Каждое грамматическое значение выражается отдельным аффиксом; аффиксы в пределах контекста, как правило, являются однозначными и регулярными. Таким образом, для разметки словоформы необходимо проанализировать структуру ее аффиксальной цепочки с привлечением словаря основ.
Грамматическая аннотация о татарской словоформе включает информацию:
- о частеречной характеристике основы словоформы;
- о совокупности морфологических признаков (формообразующих и словоизменительных аффиксах) словоформы.
Например:
- әсәрләре (әсәр-ләр-е)
- әсәр+N+PL(ЛАр)+POSS_3SG(СЫ)+Nom.
Если словоформа допускает альтернативные варианты морфологического анализа, они также даются, например:
- чаткысыдыр (чаткы-сы-дыр), где аффикс -дыр может выражать грамматическое значение как сказуемости 3 лица единственного числа, так как пробабилитива:
- чаткы+N+Sg+POSS_3SG(СЫ)+Nom+3SG(ДЫр);
- чаткы+N+Sg+POSS_3SG(СЫ)+Nom+PROB(ДЫр);
- барган (бар-ган), где аффикс -ган может выражать как значение причастия прошедшего времени, так и некатегорического прошедшего времени (перфекта):
- бар+V+PCP_PS(ГАн);
- бар+V+PST_INDF(ГАн).
Как уже отмечалось выше, морфологическая разметка текстов корпуса выполняется автоматически с использованием модуля двухуровневого морфологического анализа татарского языка, реализованного в программном инструментарии HFST (Helsinki Finite-State Transducer Technology).
Список грамматических помет, используемых в морфологической разметке корпуса, содержится в специальном файле [Система обозначений грамматических категорий]. Для обозначения морфологических категорий, выражаемых соответствующими морфемами, разработана система обозначений с учетом современных общетипологических и тюркологических исследований [Мишарский диалект 2007] в соответствии с общепринятой международной терминологией [Leipzig glossing rules].
Следует отметить, что различные нарушения регулярности морфологии татарского языка, многие из которых вызваны большим количеством неосвоенных заимствований и несовершенством современной татарской орфографии, приводят к затруднениям при автоматической обработке, так как многие морфотактические правила на этом материале не работают.
3. Поиск в подкорпусе
Поисковая система подкорпуса позволяет реализовать поиск по:
- лемме (лексеме);
- словоформе;
- набору морфологических параметров.
Поисковая система подкорпуса также поддерживает поиск минус-слов, поиск по части слова, поиск с использованием логических формул; таким образом, пользователь может задавать сложные запросы, обусловленные спецификой своего научного исследования [Невзорова, Мухамедшин, Билалов 2015].
Поиск по словоформе
Словоформа (форма слова) - слово в данной грамматической форме, лексема с заданным набором грамматических признаков:
өй (слово в форме основного падежа, не осложненное никакими аффиксами),
өйнең (слово в форме родительного падежа (генетива) единственного числа),
өем (слово с аффиксом принадлежности 1 лицу единственного числа),
өебездә (слово с аффиксом принадлежности 1 лицу множественного числа и аффиксом местно-временного падежа - локатива) и т.д.
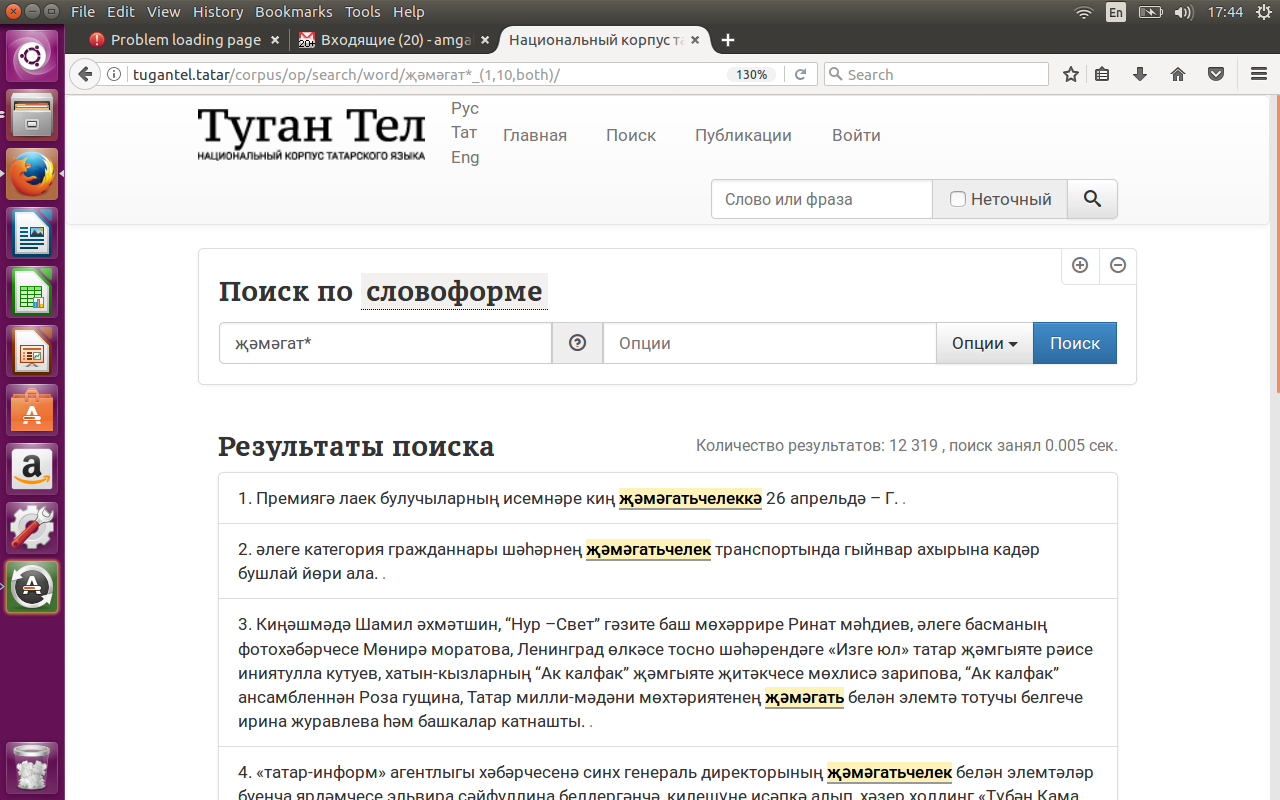
Для поиска по словоформе нужно зайти на поисковую страницу подкорпуса, нажать на кнопку “Поиск по СЛОВОФОРМЕ" и набрать в поле “СЛОВОФОРМА” нужную словоформу, например, җәмгыяте ('общество' с аффиксом принадлежности 3-ему лицу) или кайтканнар ('вернулись') и нажать на синюю кнопку “НАЙТИ” в правой части экрана. См. рисунки 1 и 2.
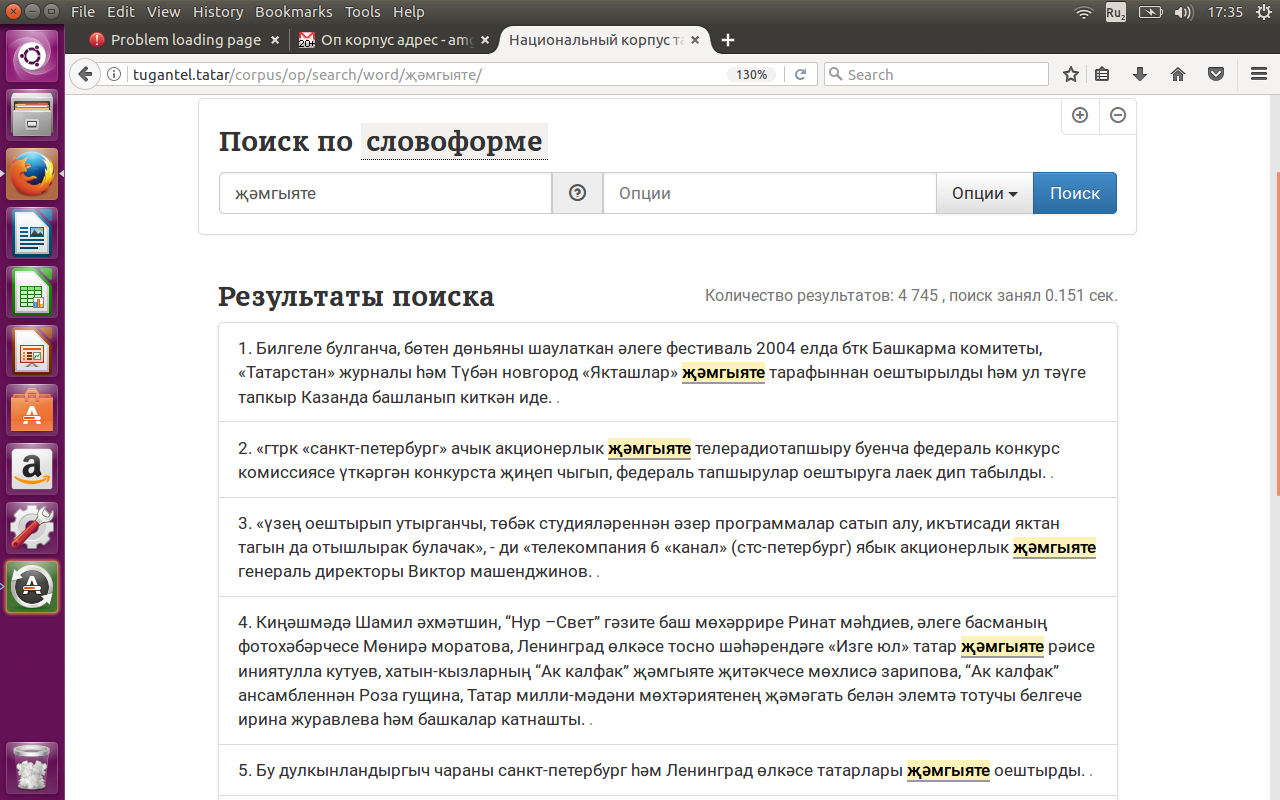
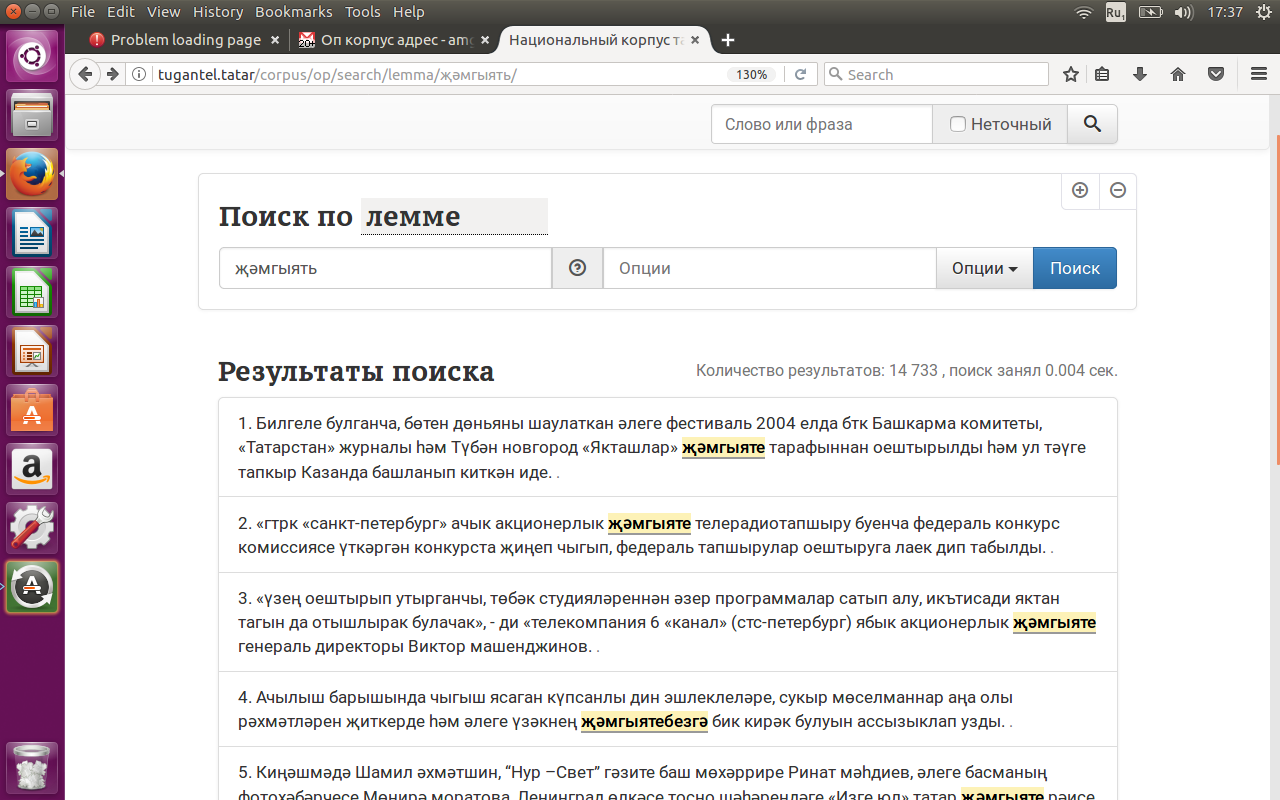
Поиск по лемме (лексеме)
Лексема (от греч. lexis – слово, выражение) - слово, рассматриваемое как единица словарного состава языка в совокупности всех его конкретных грамматических форм и выражающих их аффиксов, а также всех возможных значений (семантических вариантов); лексема - абстрактная двусторонняя единица словаря. Лексема представляет собой совокупность форм и значений, свойственных одному и тому же слову во всех его употреблениях, и характеризуется как формальным, так и смысловым единством. Так как термин лексема имеет устойчивые ассоциации с лексикологией и лексикографией, в компьютерной лингвистике для обозначения основной (начальной, исходной) формы слова используется термин лемма, а сам процесс сведения словоформы к лемме называют лемматизацией.
Соответственно, поиск по лемме - это поиск всех форм данного слова, например: өй (дом) - өй, өйдә, өйнең, өем, өебездә, өйдәге, өйләре.
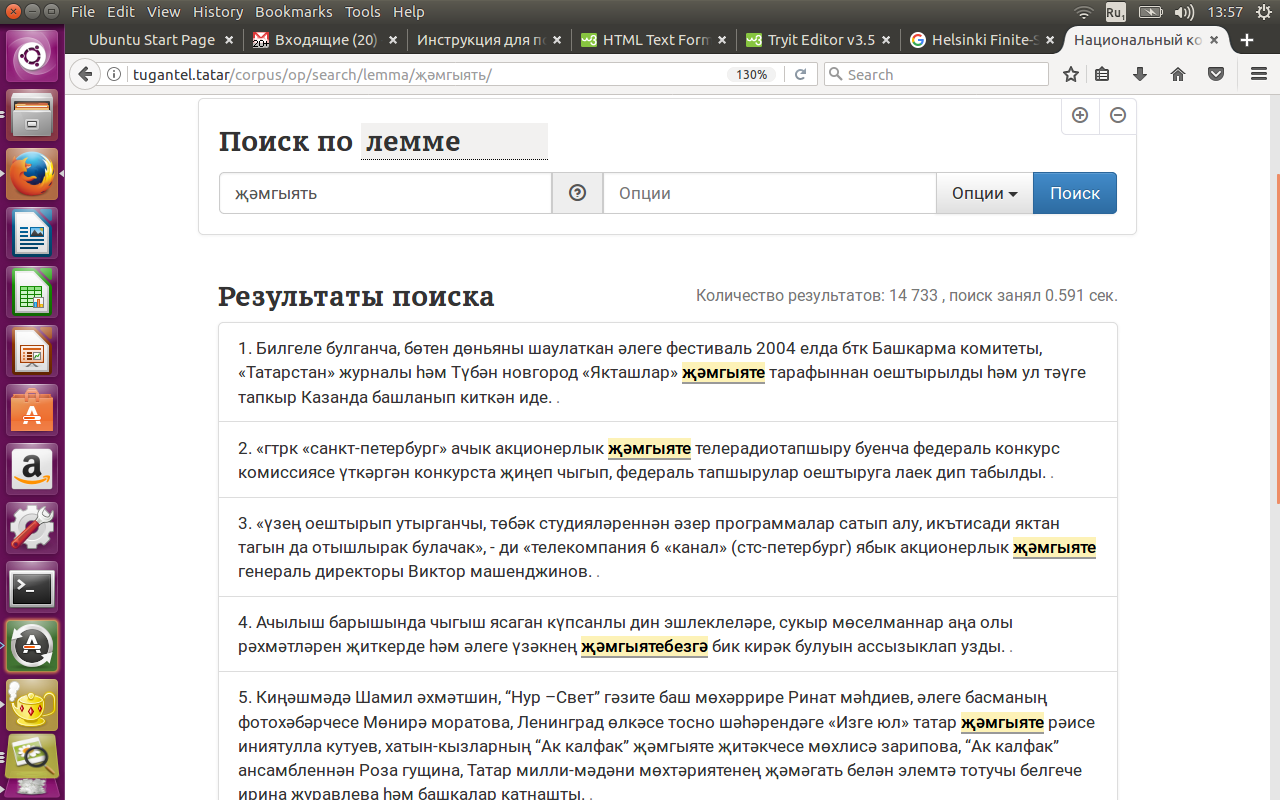
Для поиска по лемме нужно зайти на поисковую страницу подкорпуса, нажать на кнопку “Поиск по СЛОВОФОРМЕ”, выбрать “по ЛЕММЕ” и набрать в поле “СЛОВО” нужное слово, например, җәмгыять (‘общество’) и нажать на синюю кнопку “НАЙТИ”.
Для поиска татарских слов по лемме именные части речи нужно ставить в основной падеж (то есть отсечь все словоизменительные аффиксы слова). См. рисунок 3.
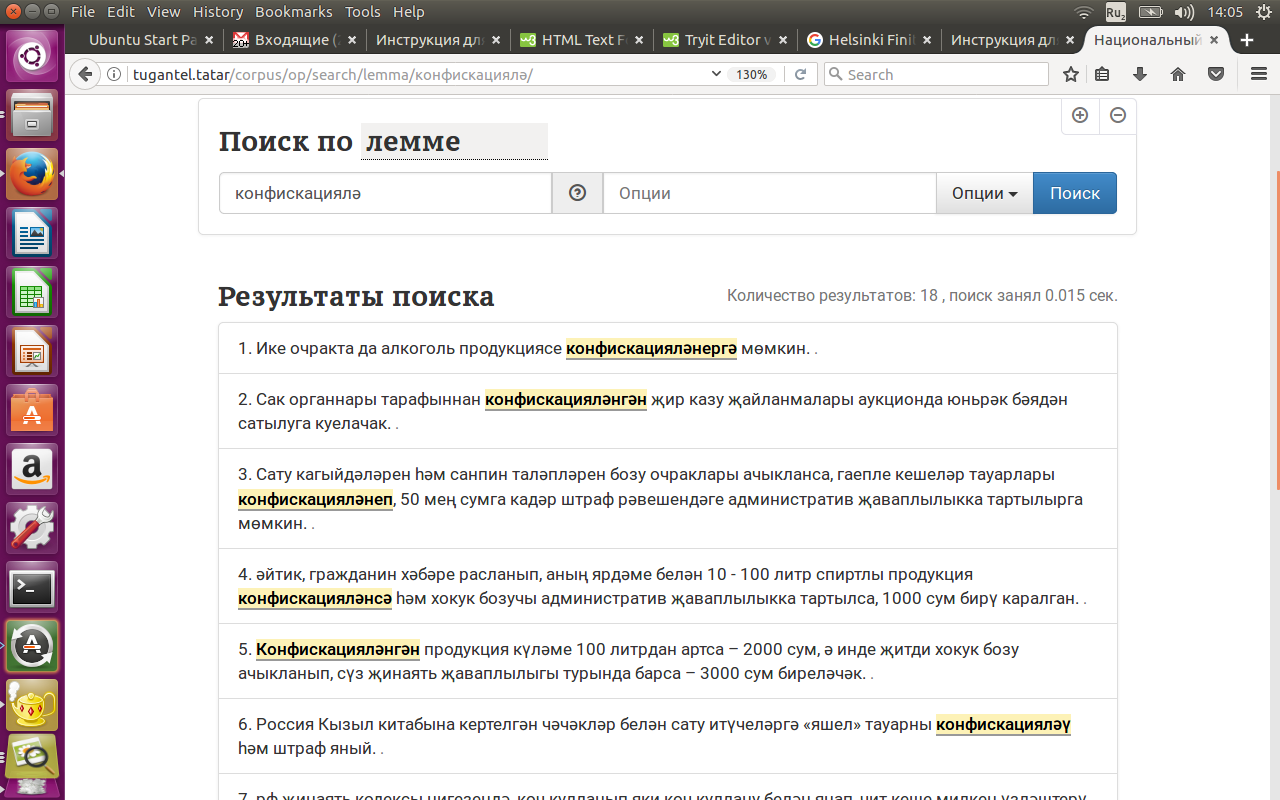
Для поиска по лемме глаголов нужно поставить слово в форму 2-го лица единственного числа повелительного наклонения (императива), так как именно императив 2-го лица единственного числа в тюркских языках представляет собой основу глагола:
конфискацияләү, конфискацияләргә - конфискациялә ('конфисковать');
кайту, кайтырга - кайт ('возвращаться, вернуться').
См. рисунок 4.
Если требуется поиск глаголов, стоящих в форме одного из залогов, нужно в качестве леммы использовать императив с аффиксом требуемого залога, например, кайтар ('вернуть'), кайтарт ('заставить вернуть'), ватыл ('ломаться'), конфискациялән ('конфисковаться, быть конфискованным'). Но, так как татарские глаголы с показателями залога недостаточно последовательно отражаются в лексикографических источниках (в том числе и в словаре корпуса, который базируется на существующих словарях), для того чтобы гарантированно найти нужную залоговую форму, надо попробовать поискать ее в двух вариантах:
- в качестве самостоятельной леммы;
- с исходной леммой (без показателя залога), дополнительно выбрав форму соответствующего залога в строке поиска грамматических признаков (см. параграф Комбинированный поиск по лемме и заданному набору грамматических признаков).
Поиск по грамматическим показателям
Поисковая система корпуса позволяет производить поиск по одному морфологическому признаку или по их совокупности.
1. Поиск по одному морфологическому признаку.
Для поиска по грамматическим признакам нужно зайти на поисковую страницу подкорпуса и нажать на кнопку “ОПЦИИ”. Затем в открывшемся окне следует выбрать нужную грамматическую категорию, выделив ее галочкой, и нажать на кнопку “СОХРАНИТЬ” внизу поля.
После этого в поле “ОПЦИИ” на основной поисковой странице должен появиться тег для выбранной категории. Далее следует нажать кнопку “ПОИСК”.
См. рисунок 5, котрый показывает поиск примеров, содержащих словоформы с аффиксом направительного падежа (директива).
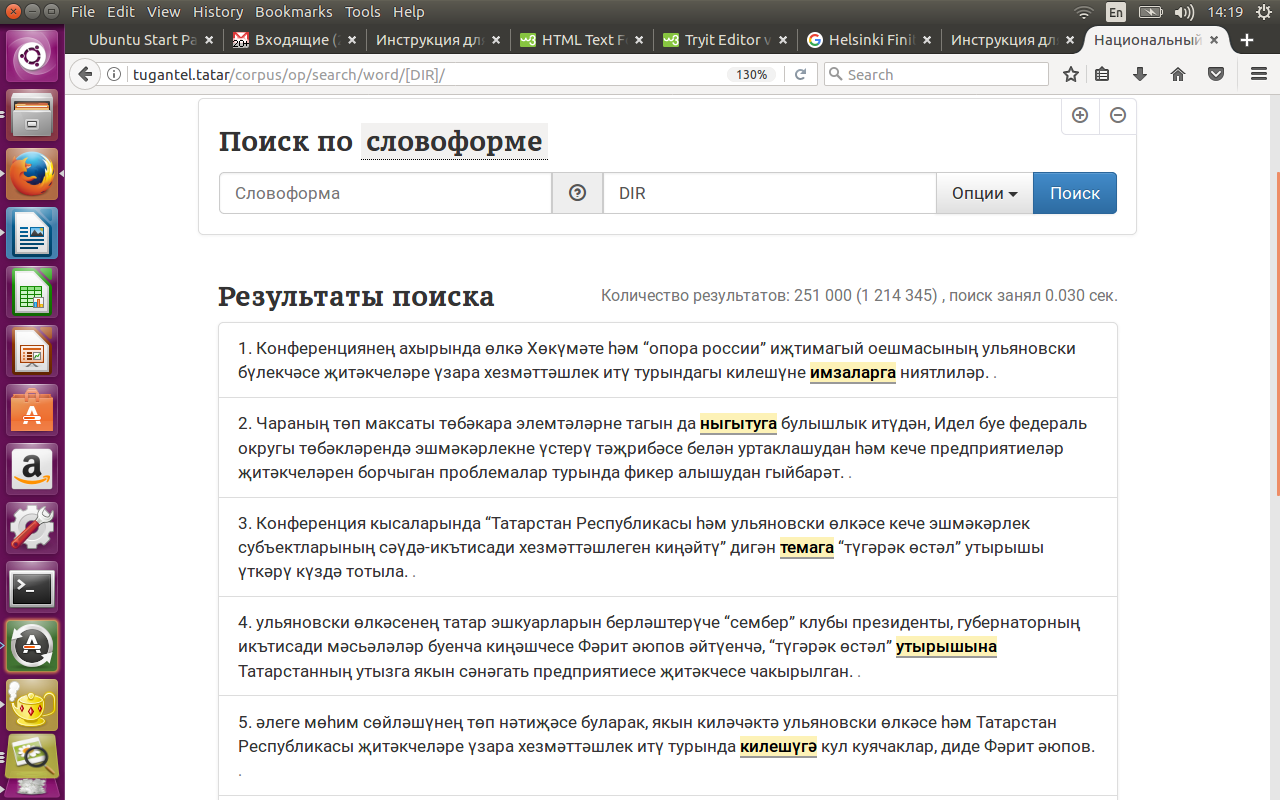
2. Поиск по совокупности морфологических признаков
Для поиска по совокупности морфологических категорий нужно зайти на поисковую страницу подкорпуса и нажать на кнопку “ОПЦИИ”. Затем в открывшемся окне следует выбрать нужные грамматические категории, выделив их галочкой, и нажать на кнопку “СОХРАНИТЬ” внизу поля. После этого в поле “ОПЦИИ” на основной поисковой странице должны появиться наборы тегов для выбранных категорий. Далее следует нажать кнопку “ПОИСК”.
См. рисунок 6.
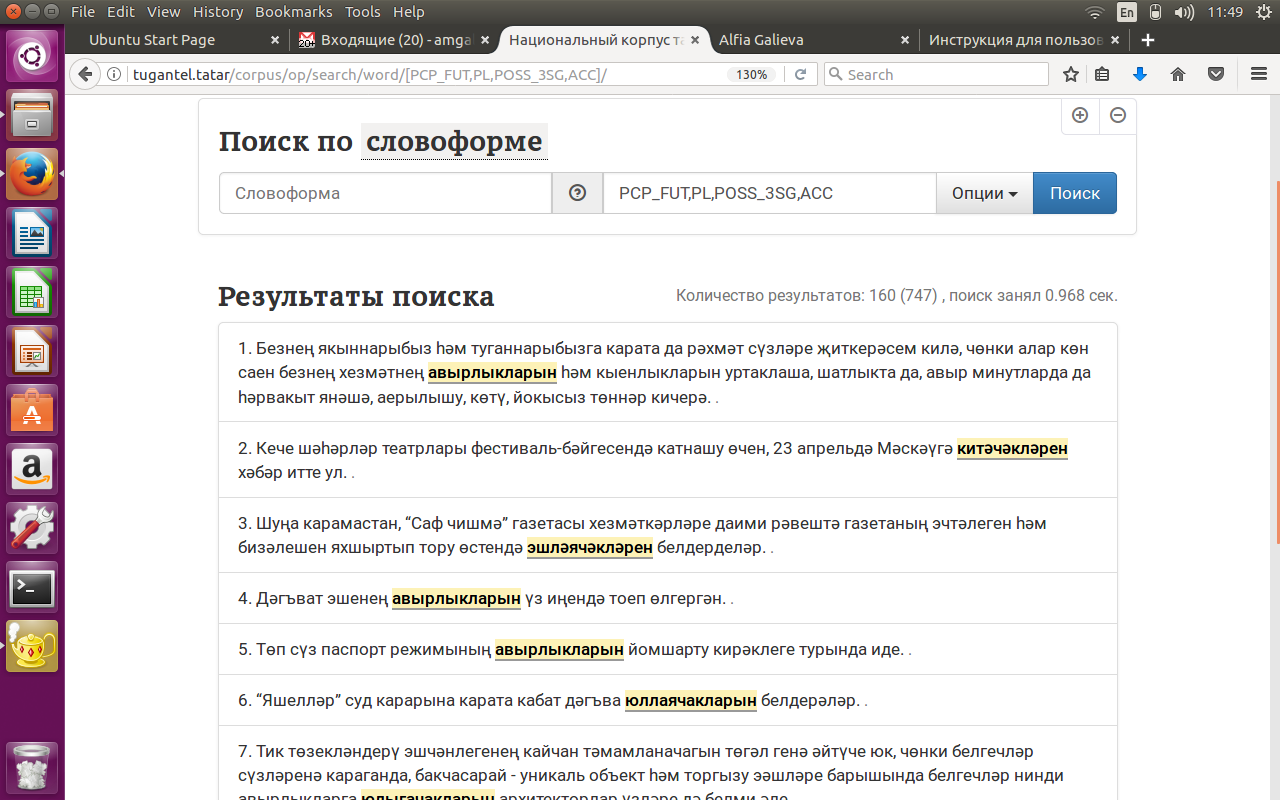
Для тех, кто уже хорошо знаком с системой грамматической разметки ТНК, существует еще один способ: непосредственно в поле “ОПЦИИ” набрать обозначения нужных категорий латинскими прописными буквами через запятую (без пробелов!). Например, для глаголов определенного будущего времени с аффиксом множественного числа поисковый запрос будет выглядеть следующим образом:
V,FUT_DEF,3PL
После этого следует нажать кнопку “ПОИСК”.
Комбинированный поиск по лемме и заданному набору грамматических признаков
Чтобы произвести поиск по конкретной лемме и заданному набору грамматических признаков, нужно:
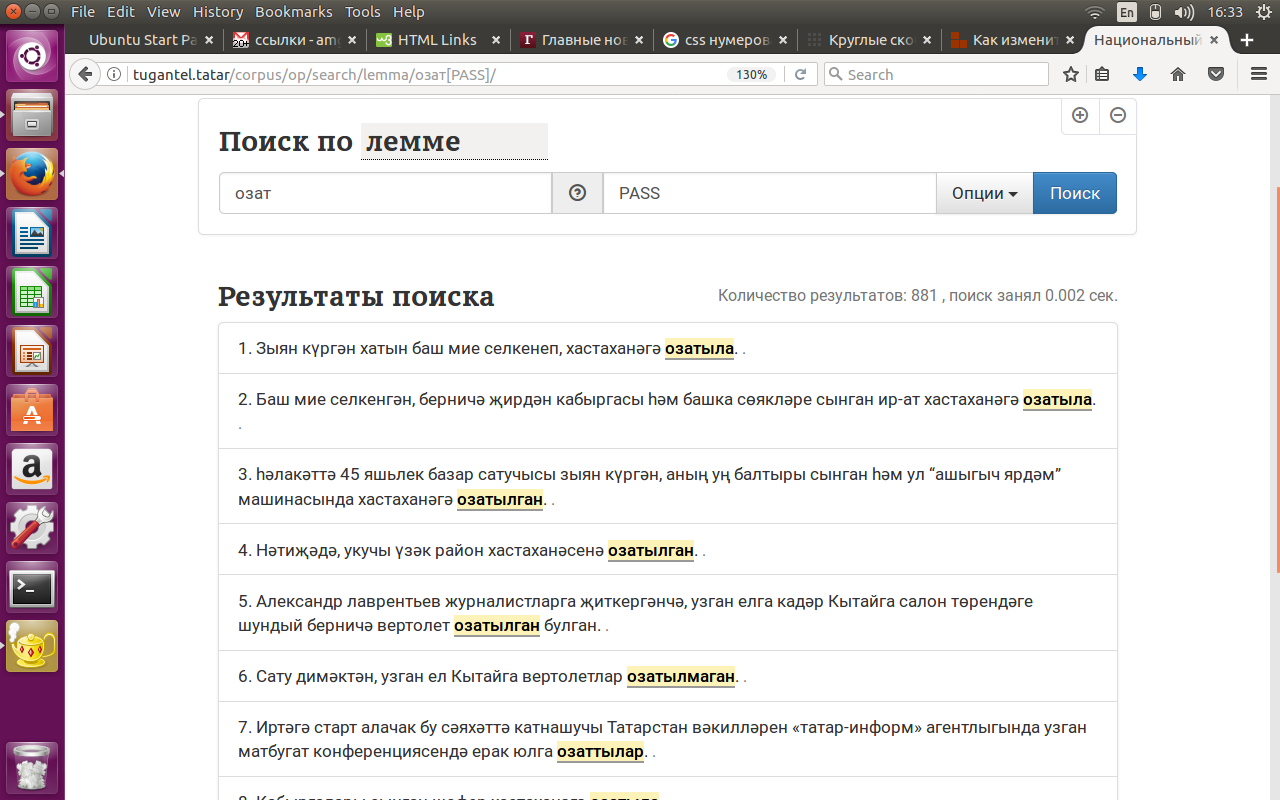
- зайти на поисковую страницу подкорпуса, нажать на кнопку “Поиск по СЛОВОФОРМЕ”, выбрать “Поиск по ЛЕММЕ” и набрать в поле “СЛОВО” нужное слово, например, озат (‘провожать’);
- нажать на кнопку “ОПЦИИ” и в открывшемся окне выбрать нужную грамматическую категорию, выделив ее галочкой, и нажать на кнопку “СОХРАНИТЬ” внизу поля;
- нажать на кнопку “ПОИСК”.
См. рисунки 7 и 8.
Сложные поисковые запросы с логическими формулами
Поисковая система корпуса поддерживает поиск с использованием логических формул. В качестве логических операторов используется конъюнкция (логическая операция, по смыслу максимально приближенная к союзу «и»), дизъюнкция (логическая операция, по смыслу максимально приближенная к союзу «или») и отрицание.
Для поиска нужно пользоваться системой грамматической разметки ТНК. Для усложнения структуры поискового запроса могут быть использованы скобки.
Пример 1. Поисковый запрос с использованием конъюнкции.
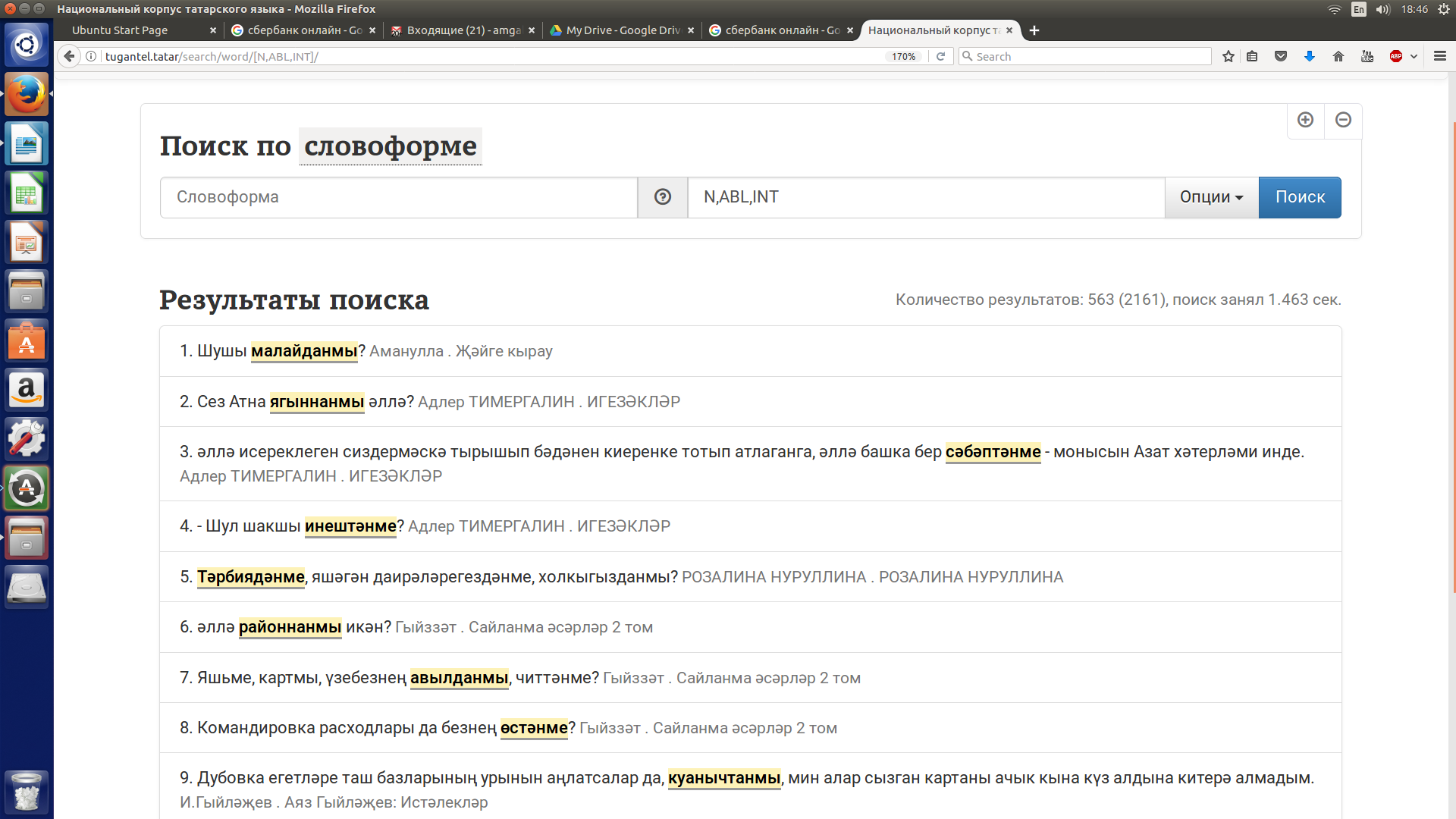
Допустим, нужно извлечь контексты, содержащие существительные с аффиксом исходного падежа (аблатива) и аффиксом общего вопроса (интеррогатива).
В строке поиска грамматических категорий нужно набрать N,ABL,INT (прописными буквами без пробелов через запятую) или воспользоваться кнопкой “ОПЦИИ” для выбора соответствующих морфологических признаков.
См. рисунок 9.
Пример 2. Поисковый запрос с использованием дизъюнкции.
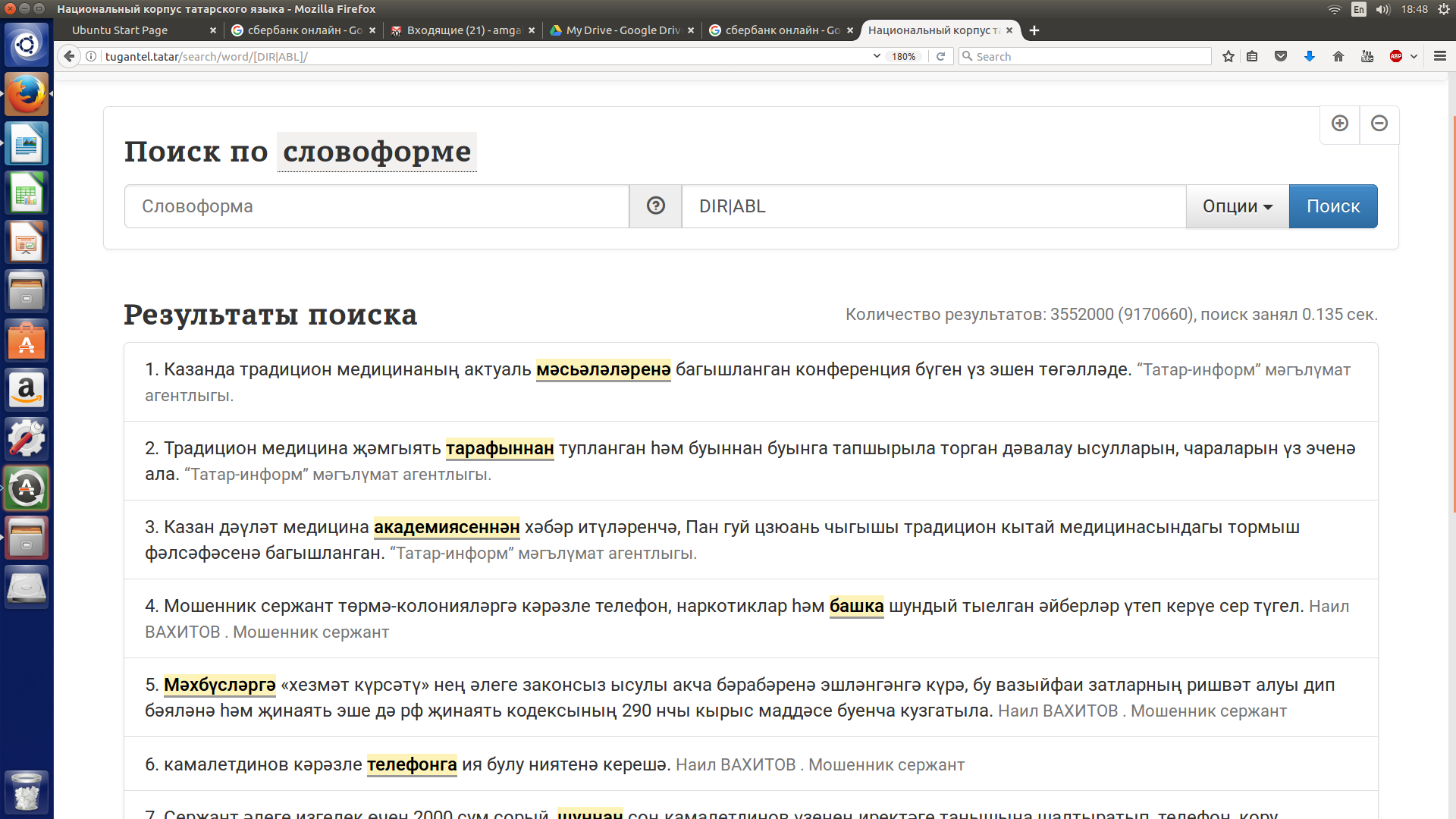
Допустим, нужно извлечь контексты, содержащие слова с аффиксом направительного падежа (директива) или с аффиксом исходного падежа (аблатива).
В строке поиска грамматических категорий нужно набрать DIR|ABL (прописными буквами без пробелов через вертикальную черточку - знак |) или воспользоваться кнопкой “ОПЦИИ” для выбора соответствующих морфологических признаков.
См. рисунок 10.
Пример 3. Поисковый запрос с использованием конъюнкции и дизъюнкции.
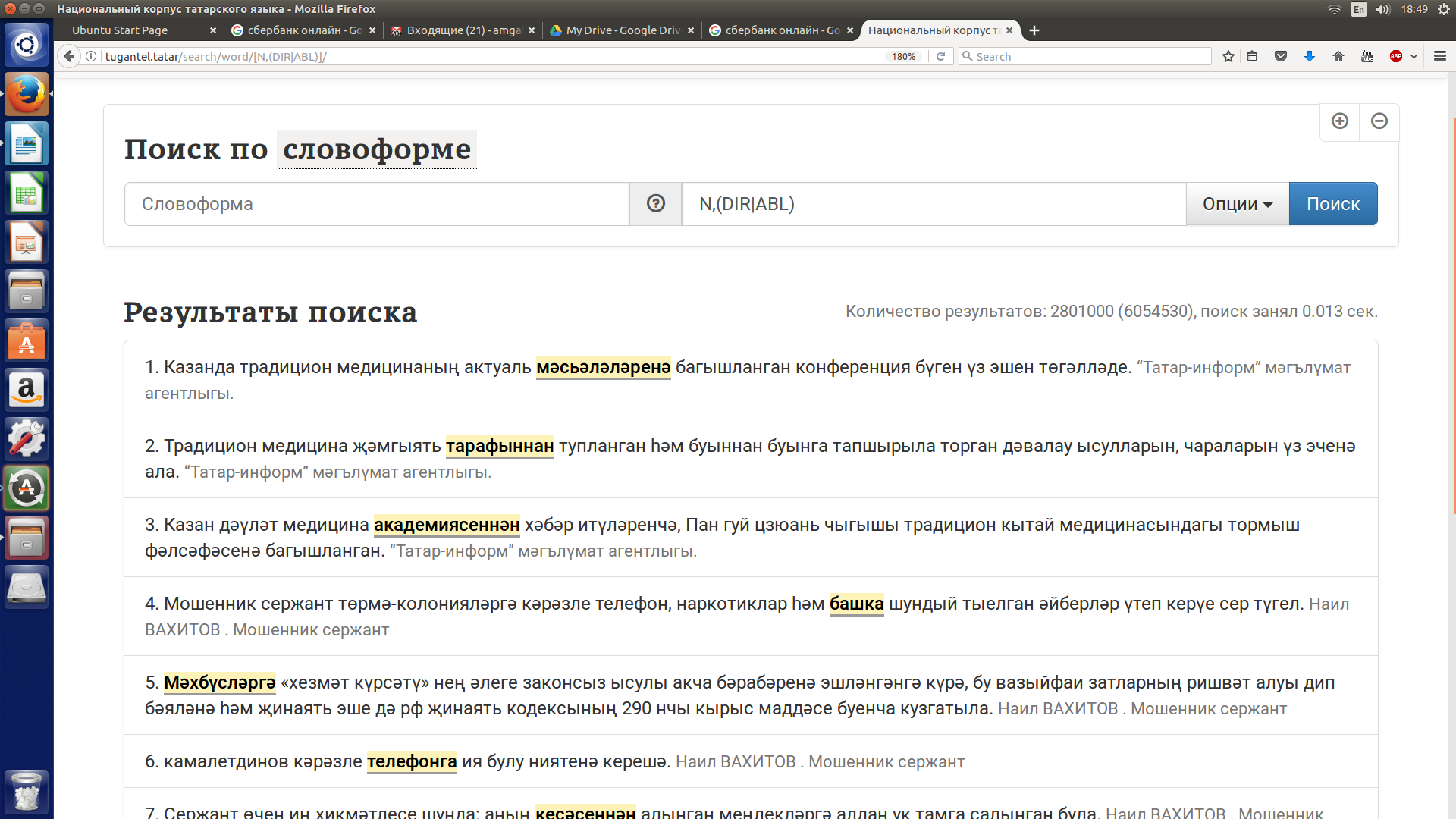
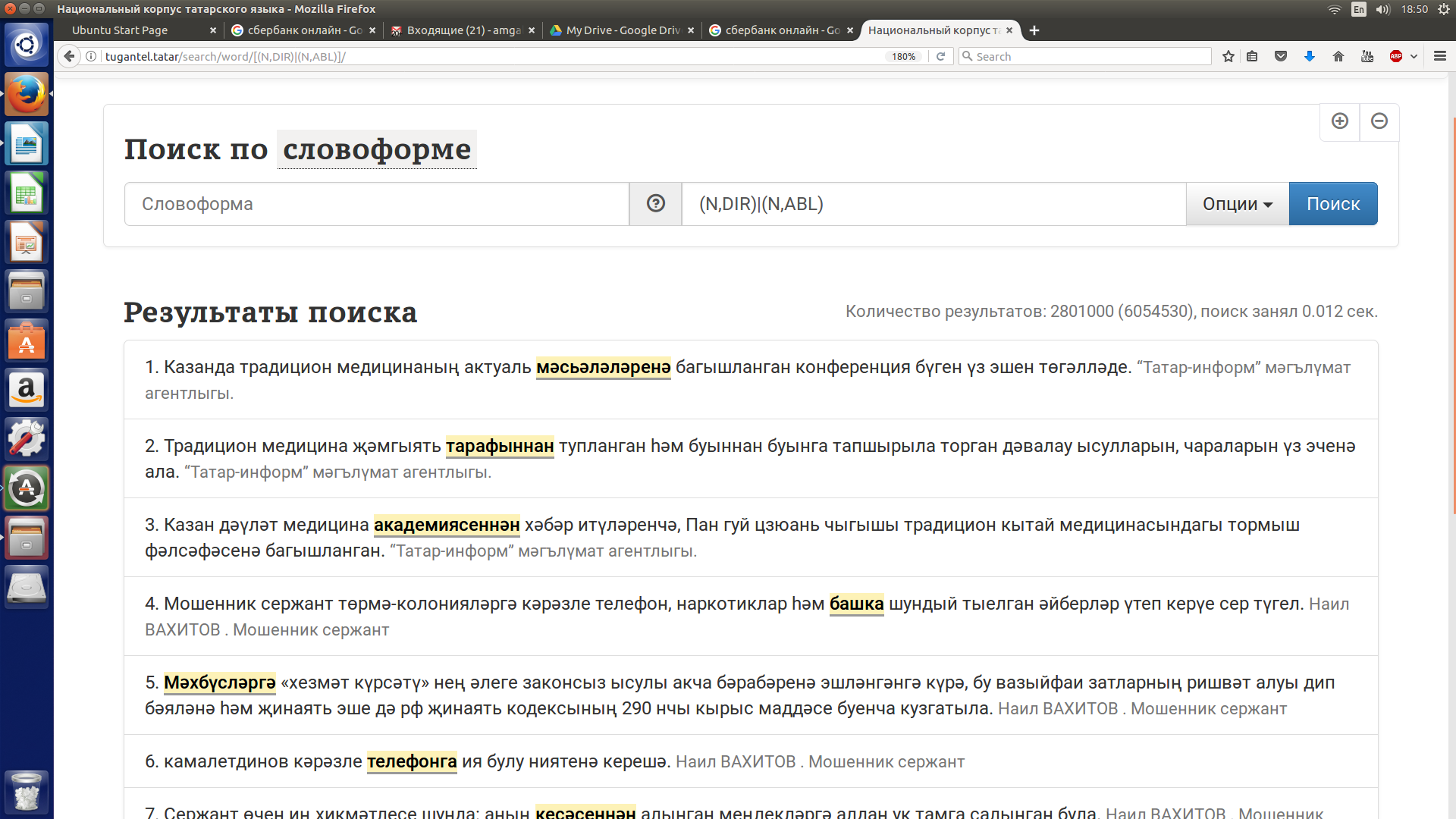
Допустим, нужно извлечь контексты, содержащие существительные с аффиксом направительного или исходного падежа. Запрос предполагает использование конъюнкции и дизъюнкции и может быть представлен в виде двух альтернативных формул: 1) N,(DIR|ABL); 2) (N,DIR)|(N,ABL), которые представлены на рисунках 11 и 12.
Пример 4. Поисковый запрос с использованием отрицания.
В качестве знака для отрицания используется восклицательный знак (!)
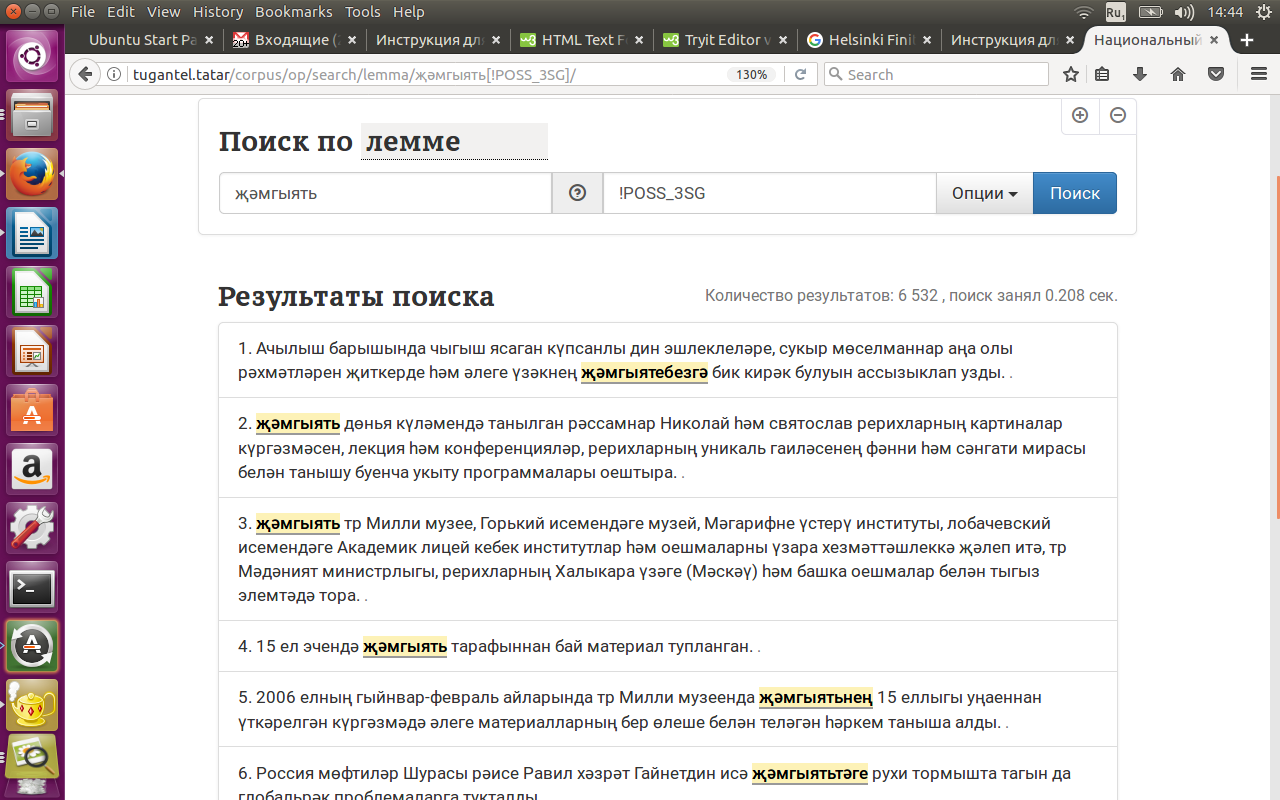
Допустим, надо найти примеры использования слова җәмгыять ('общество'), исключая формы с аффиксом принадлежности 3-ему лицу единственного числа (POSS_3SG).
Для этого нужно использовать комбинированный запрос: поиск по лемме (җәмгыять), совмещенный с поиском с отрицанием. В строке выбора грамматических категорий нужно набрать или выбрать POSS_3SG и поставить перед ним знак отрицания (!). См. рисунок 13.
Поиск со звездочкой
Знак * используется для поиска по нестрого заданным параметрам и означает 0 и более произвольных символов. Для поискового запроса в поле "СЛОВО" нужно набрать строго задаваемую часть слова, а для нестрого задаваемой части слова нужно поставить знак * (см. рисунок 14).
Поиск со звездочкой особенно удобен для случаев, когда вы знаете основу или корень слова, но не уверены, какие производные слова или формы используются в текстах, например, театрлаштырган или театрлаштырылган ("театрализованный")?
Тогда можно задать ту часть слова, которая вам известна, и поставить знак * (используем поиск по словоформе), например, театрлаш* .
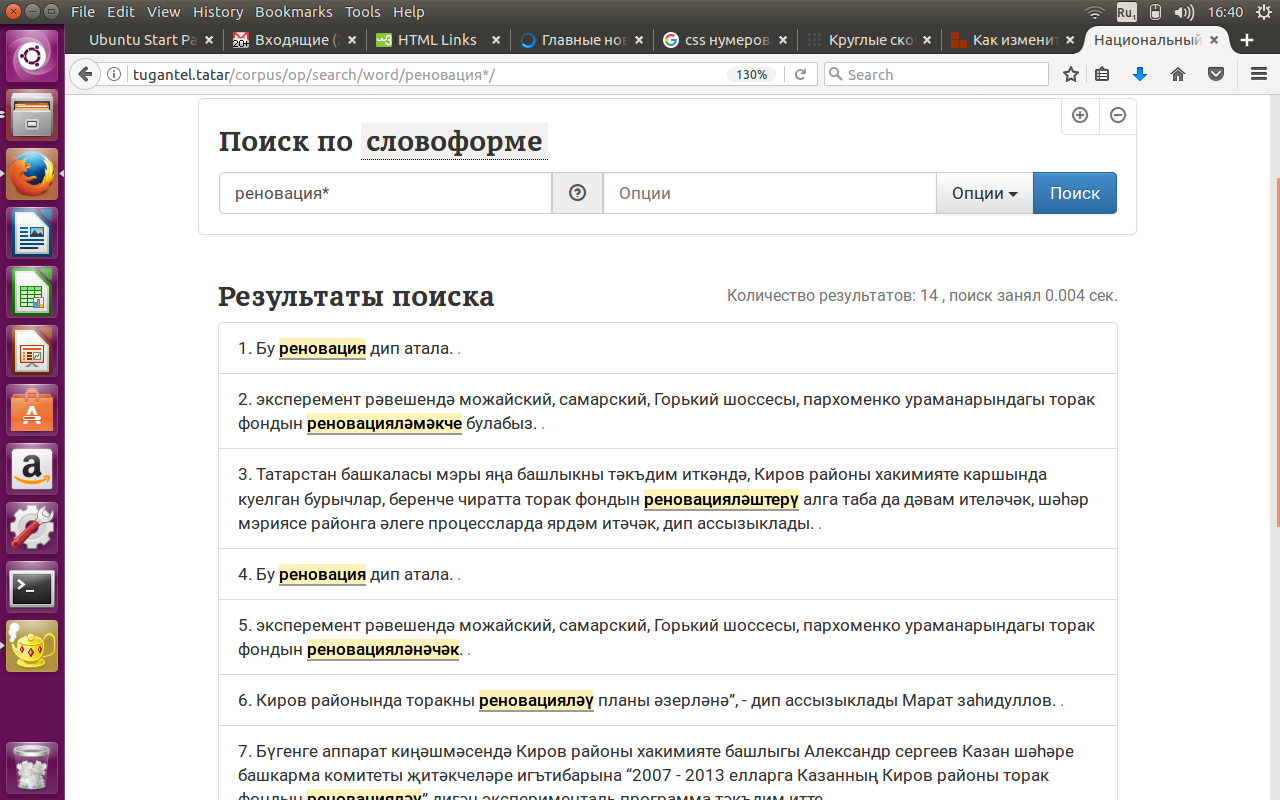
Поиск со звездочкой очень удобно использовать для получения контекстов с редко используемыми в речи словами (архаизмы, неологизмы и пр.), когда основа слова может отсутствовать в словаре корпуса (в этом случае поиск по лемме не даст результатов), а перебрать все потенциальные варианты затруднительно. Например, для слова реновация поиск по лемме не дает результатов, а поисковый запрос реновация* позволяет получить все нужные контексты (см. рисунок 15).
Также поиск со звездочкой удобен для поиска слов с заданной цепочкой аффиксов, например *ачаклардыр (комбинация аффиксов, выражающих значение определенного будущего времени, множественного числа и пробабилитива). Такой способ поиска часто позволяет избежать необходимости построения сложных формул для поиска по морфологическим категориям. Следует помнить, что, для того чтобы получить все примеры с заданной аффиксальной цепочкой из корпуса, надо дополнительно внести в строку поиска по словоформе фонетический вариант с гласными переднего ряда (с учетом сингармонизма гласных), например *әчәкләрдер для примера выше.
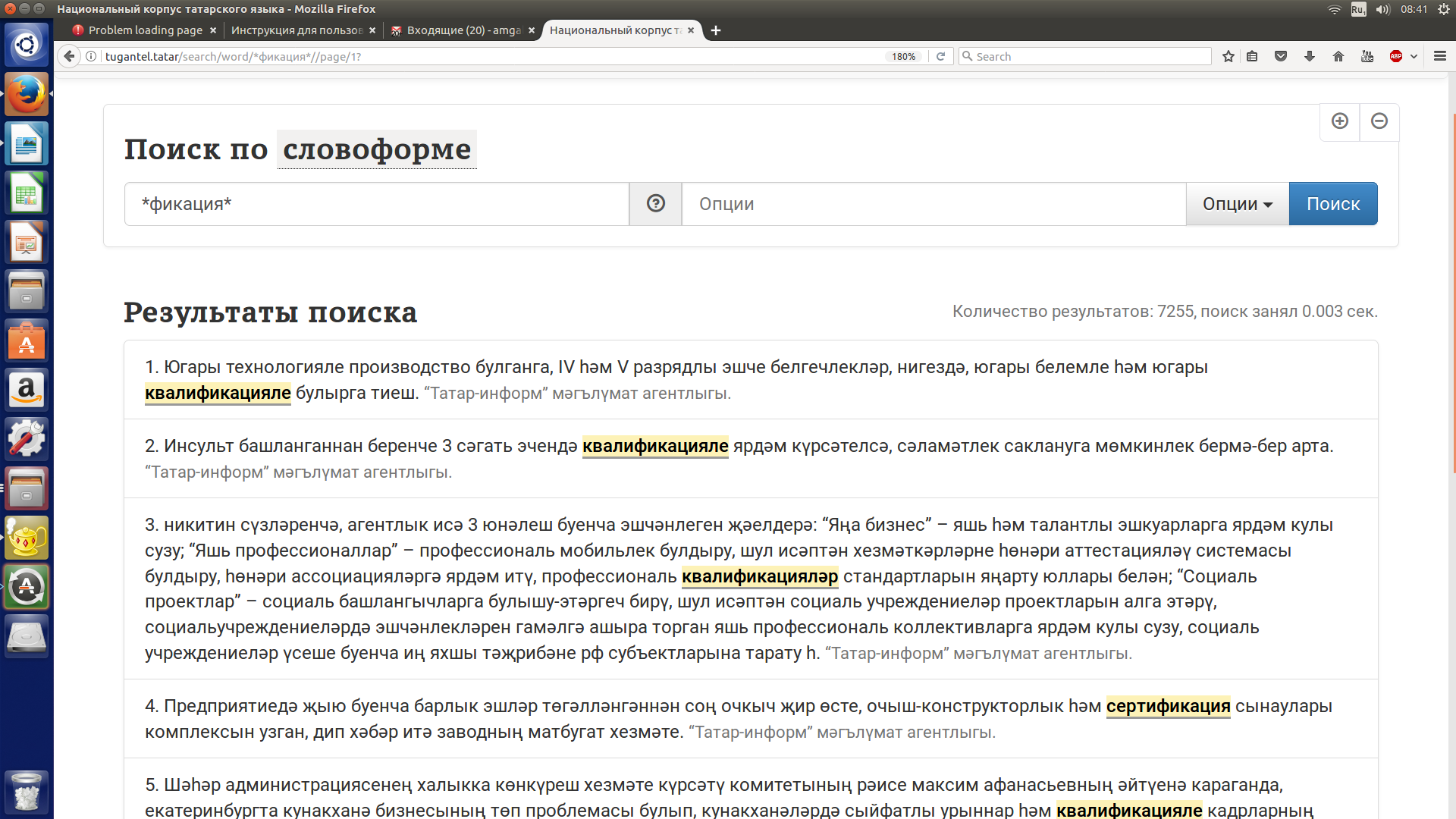
Поиск со звездочкой может быть использован для обозначения начала, конца или середины словоформы (леммы), также можно использовать одновременно несколько знаков *, чтобы задать требуемый поисковый запрос. Допустим, нужно найти используемые в татарском языке сложные слова с суффиксоидом -фикация, когда неизвестен корень и словообразующие и словоизменительные аффиксы. См. рисунок 16.
Поиск с минус-словами
Минус-слова - это слова, которые требуется исключить из поиска. Корпус-менеджер ТНК допускает два основных способа поиска с использованием минус-слов; покажем это на примерах.
1. Поиск по словоформе.
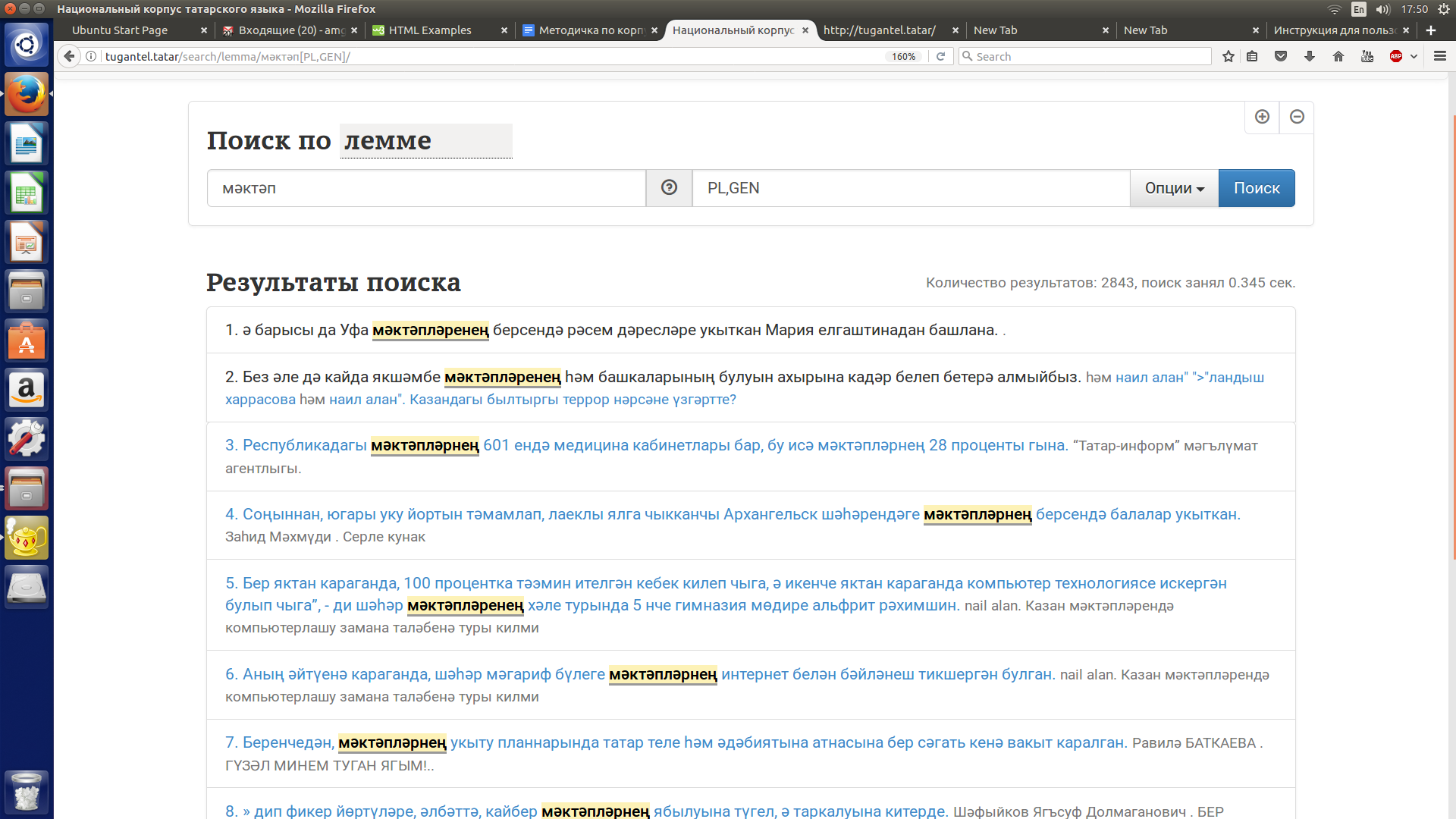
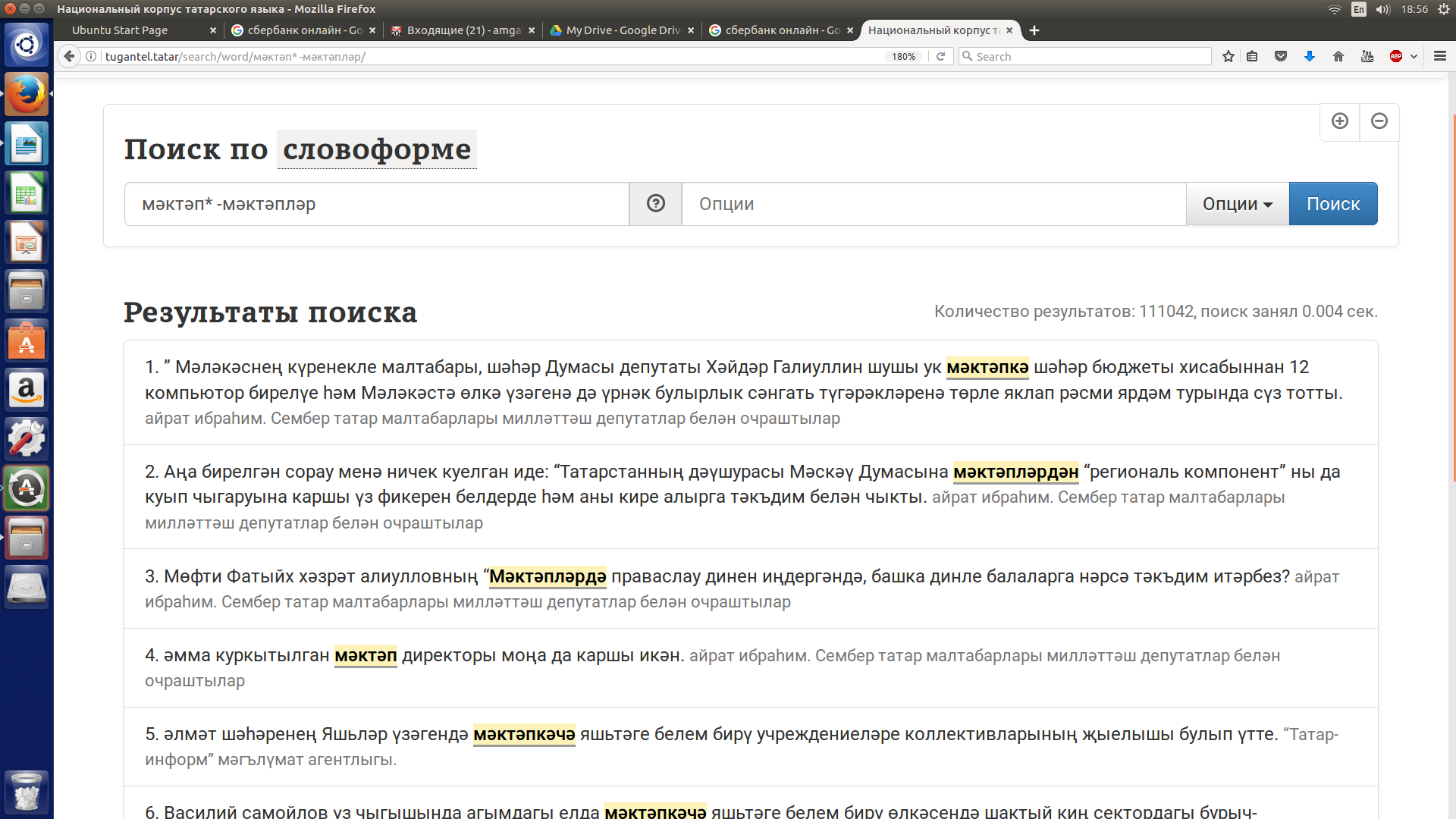
Допустим, надо найти все контексты, содержащие слово мәктәп ('школа'), исключая все контексты, содержащие словоформу мәктәпләр.
В строку поиска по словоформе нужно ввести следующий запрос: мәктәп* -мәктәпләр (мәктәп, знак звездочки, пробел, знак “минус” (дефис), исключаемая словоформа мәктәпләр). См. рисунок 17.
2. Поиск по лемме.
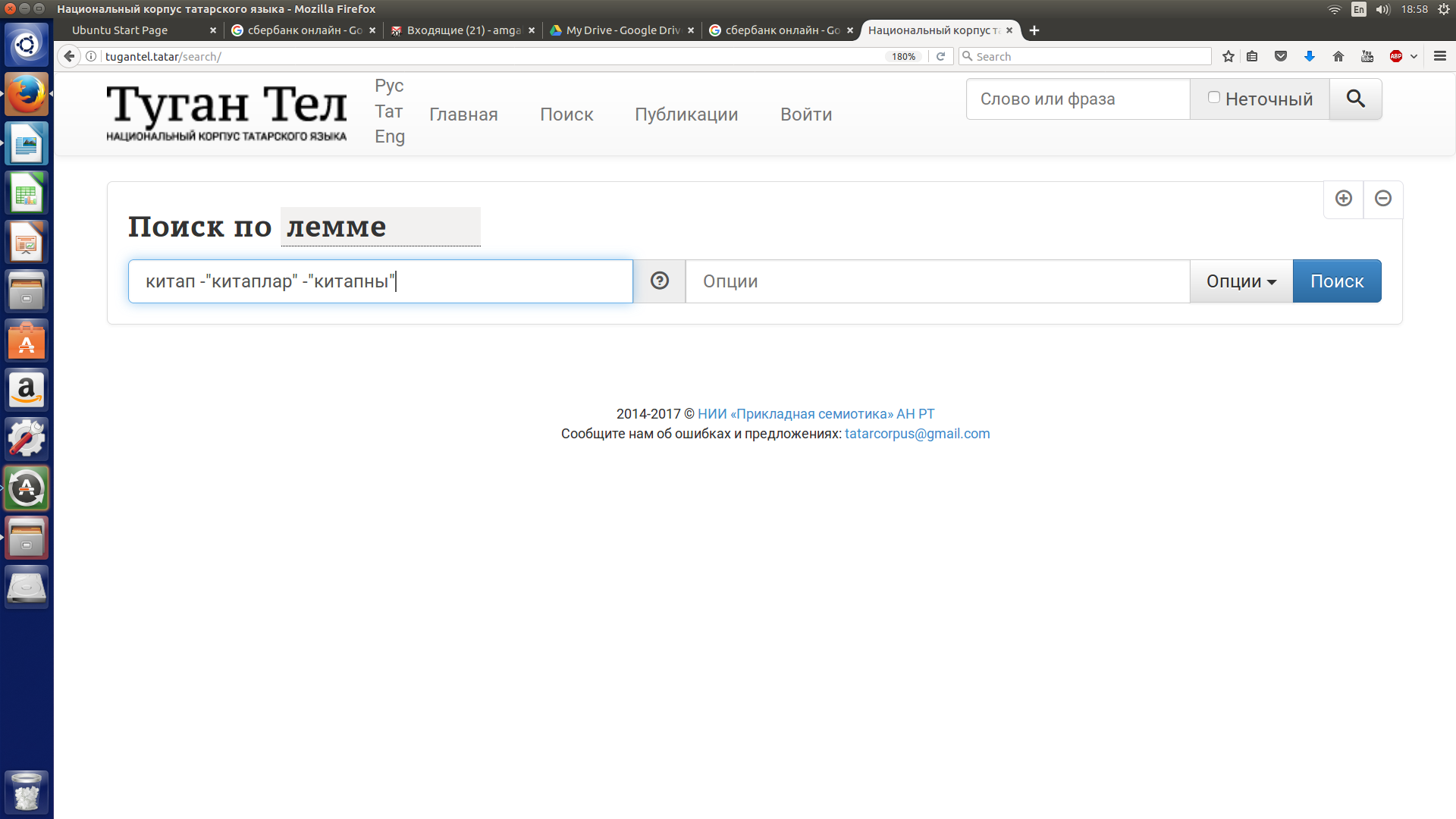
При поиске с минус-словами по лемме используется знак “ (кавычки), что означает, что будут исключены словоформы в кавычках; указанные без кавычек минус-слова будут считаться леммами.
Рассмотрим это на примере.
Допустим, нужно найти все контексты со словом китап, исключая контексты со словоформами китапны и китаплар. В строке поиска по лемме нужно ввести запрос следующего вида: китап -"китаплар" -"китапны". См. рисунок 18.
Знак “ (кавычки) можно использовать также при поиске с минус-словами по словоформам, в этом случае кавычки означают исключение указанных лемм.
Поиск с минус-словами удобен тем, что позволяет исключить из результатов поискового запроса примеры с ненужными частотными словами (словоформами), зашумляющие данные.
Таким образом, корпус-менеджер ТНК позволяет осуществлять сложные запросы, комбинируя различные логические операторы и параметры поиска - по лемме, лексеме, минус-словам, и т.п., что позволяет получить именно те лингвистические данные, которые требуются пользователю корпуса.
Поиск с учетом расстояния между словами
Корпус-менеджер ТНК позволяет задавать сложные поисковые запросы с учетом расстояний между словами.
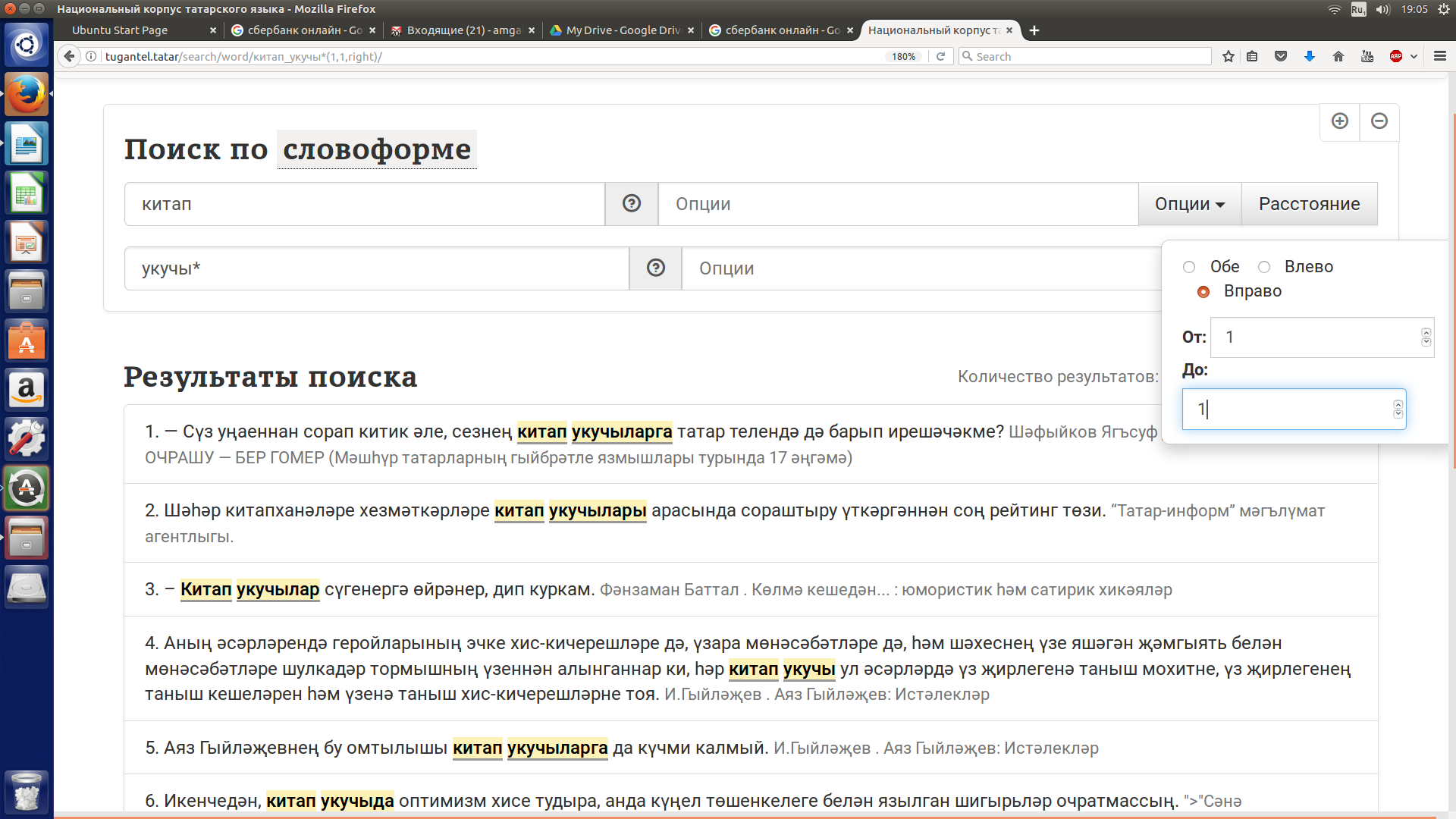
Допустим, нужно найти все контексты, содержащие словосочетание китап укучы ('читатель книги', 'читатель').
Используем поиск по словоформе и в строке поиска вводим китап. Далее нужно заполнить поле для второго компонента словосочетания, для чего нужно открыть новое поле. Щелкаем знак + в правой верхней части экрана и в открывшемся окне набираем слово укучы* (знак * нужен для того, чтобы получить все требуемые словоформы для укучы). Далее нужно задать расстояние между словами; для этого нужно щелкнуть кнопку “РАССТОЯНИЕ” в правой верхней части экрана и в открывшемся окошке выбрать расстояние “ОБЕ”, “ВЛЕВО” или “ВПРАВО” и задать нужное расстояние, в нашем случае -” ВПРАВО” и расстояние от 1 до 1. См. рисунок 19.
Далее нужно еще раз щелкнуть кнопку “РАССТОЯНИЕ”, чтобы закрыть окно с параметрами расстояния, и нажать на кнопку “ПОИСК”.
При использовании поиска по лемме для китап укучы будут получены контексты, содержащие не только все возможные формы второго компонента словосочетания китап укучы, но и все возможные формы первого компонента (китабын укучыга, китапларын укучылар, китабын укучыга, китапларын укучылар и т.п.).
Поиск с учетом расстояния между компонентами допускает использование всех описанных выше параметров поискового запроса, комбинируя их различным образом.
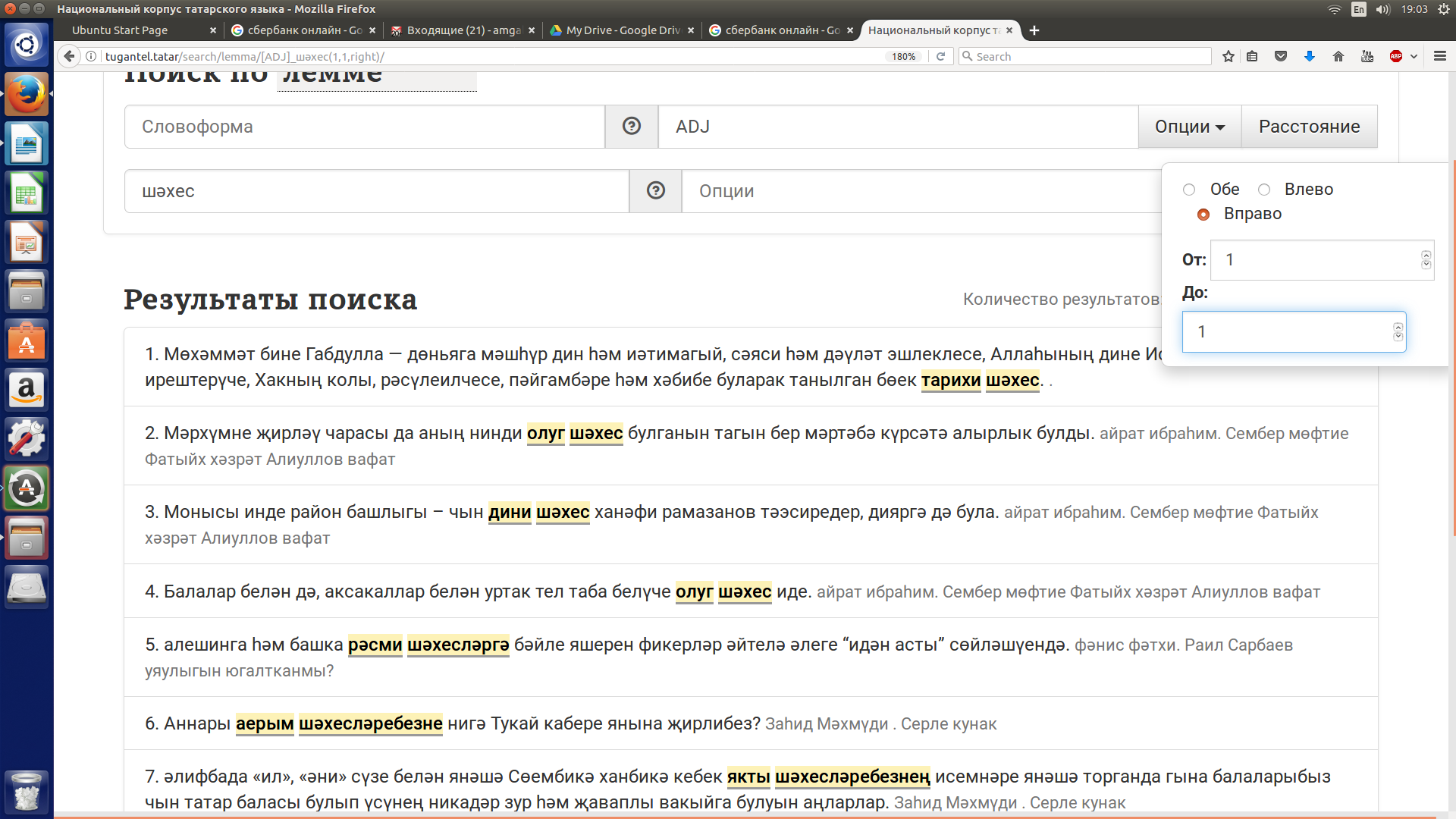
Допустим, нужно узнать, с какими прилагательными сочетается существительное шәхес (личность). В этом случае в качестве первого компонента нужно задать прилагательное, используя обозначение ADJ, а второй компонент шәхес искать по лемме (не забудьте задать требуемый параметр расстояния между словами - в данном случае вправо от 1 до 1). См. рисунок 20.
Поиск с учетом расстояния между словами позволяет получать требуемые языковые единицы, состоящие из двух и более раздельно оформленных компонентов.
При задании расстояния между компонентами можно использовать также число 0. Так, задавая поисковый запрос следующего вида:
первый компонент - N (существительное), второй компонент - V (глагол), расстояние между компонентами - 0,
можно получить грамматические омонимы - словоформы, которые, в зависимости от контекста, могут быть интерпретированы и как существительные, и как глаголы в соответствующей форме (например, такие, как басма - басма, казан - казан, таба - таба и т.п.).
4. Задания
1. Определите частотность употребления слов суд и мәхкәмә ‘суд’ в Татарском национальном корпусе и в Общественно-политическом подкорпусе:
- по словоформе (основной падеж);
- по лемме.
2. Изучите типичные контексты использования слов суд и мәхкәмә ‘суд’ в Татарском национальном корпусе и в Общественно-политическом подкорпусе и докажите, что эти существительные являются абсолютными синонимами. В качестве критериев синонимичности можно использовать совокупность признаков: лексическое значение, контексты употребления и коллокации, стиль и тип текстов, взаимозаменяемость слов в пределах контекста.
3. Изучите метаданные корпуса и сделайте вывод о том, какие информационные ресурсы предпочитают использовать в своих текстах слово суд, а какие - слово мәхкәмә?
4. Используя корпусные данные, определите основные значения слова маташу ‘пытаться’. Имеются ли грамматические ограничения (например, формы управления глагола) для каждого значения? Сделайте вывод о том, наблюдаете ли вы полисемию или омонимию?
5. Используя корпусные данные, определите основные значения слова мавыгу ‘увлекаться’. Имеются ли грамматические ограничения (например, формы управления глагола) для каждого значения? Сделайте вывод о том, наблюдаете ли вы полисемию или омонимию?
6. Используя корпусные данные, определите модели управления и семантические роли основных актантов глагола сайлау ‘выбирать’. Результаты вашего исследования оформите в виде таблицы. Подумайте, какую еще информацию о глаголе можно зафиксировать в этой таблице.
7. Определите количество контекстов, в которых слово дәүләт ‘государство’ использовано
- с аффиксом принадлежности 3-му лицу (другие аффиксы отсутствуют);
- с аффиксом множественного числа и аффиксом принадлежности 3-му лицу, но без падежных аффиксов;
- с аффиксом принадлежности 3-му лицу и с любыми падежными аффиксами;
- с аффиксом общего вопроса (словоформа может содержать любые другие аффиксы, кроме аффикса принадлежности 3-му лицу).
8. Найдите все местоимения, имеющие аффикс компаратива.
9. Найдите все существительные, имеющие любые аффиксы косвенных падежей, но не имеющие аффиксы принадлежности.
10. Найдите словоформы, в которых аффикс -лЫК имеет значение возможности совершения действия (поссибилитива). Какой частью речи должна быть основа этих словоформ?
11. Как должен быть построен поисковый запрос, чтобы найти контексты, в которых аффикс направительного падежа используется в качестве средства связи придаточного предложения с главным? Введите такой запрос в строку поиска по морфологическим признакам и проверьте корректность результатов. При необходимости подкорректируйте свой поисковый запрос.
12. Найдите в корпусе контексты, в которых слова күп милләтле и күпмилләтле отличаются написанием (слитно-раздельно). Какой вариант написания вы считаете более правильным? В качестве дополнительного источника обратитесь к словарям татарского языка.
13. Подготовьте список слов, которые в современном татарском языке имеют неустоявшееся или вариативное написание (например, вазифа - вазыйфа ‘должность’, табиб - табип ‘врач’). Посмотрите по корпусу распределение вариантов написания, для каждого случая выбирая нужный вариант поискового запроса.
14. Сравните частотность таких синонимических пар слов, как политик - сәяси ‘политический’’, экономика - икътисад ‘экономика’, республика - җөмһүрият ‘республика’. Как можно объяснить полученные данные?
15. Посмотрите в имеющихся корпусах татарского языка, как распределена частотность использования языковых единиц, обозначающих средства массовой информации (масса-күләм мәгълүмат чаралары, гаммави/гаммәви мәгълүмат чаралары, киңкүләм мәгълүмат чаралары, күмәк мәгълүмат чаралары). Изучите метаданные корпусов. Какие выводы можно сделать о терминологических предпочтениях отдельных авторов и информационных ресурсов в целом?
16. Приведите примеры синонимичных терминов в татарском языке (однокомпонентных и составных). Проверьте частотность каждого термина, используя текстовые коллекции татарских корпусов. При поиске используйте поиск со звездочкой (для изменяемого компонента).
17. Найдите словосочетания, построенные по модели прилагательное + существительное.
18. Найдите контексты, в которых слово дәүләт ‘государство’ имеет примыкающее к нему прилагательное.
19. Найдите контексты, в которых слово дәүләт ‘государство’ стоит в конструкциях типа изафет-3 в качестве второго компонента.
20. Найдите контексты, в которых слово дәүләт ‘государство’ стоит в конструкциях типа изафет-2 в качестве второго (определяемого) компонента.
21. Найдите контексты, в которых слово дәүләт ‘государство’ стоит в конструкциях типа изафет-2 в качестве определяемого компонента и одновременно имеет примыкающее к нему слева слово с аффиксом -лЫ.
22. Найдите контексты, в которых слово дәүләт ‘государство’ стоит в конструкциях типа изафет-3 в качестве первого (определяющего) компонента.
23. Постройте сложный поисковый запрос (серию запросов), позволяющий найти контексты, в которых сообщается о том, кто и от кого получает взятки.
24. Постройте сложный поисковый запрос (серию запросов), который позволяет найти контексты, сообщающие, о чем пишут газеты.
25. Постройте поисковый запрос, в которых словосочетание ислам дине ‘ислам’ примыкает к существительному с аффиксом множественного числа и аффиксом принадлежности 3-му лицу.Обратите внимание на то, что нужно получить все грамматически допустимые формы искомого словосочетания, встречающиеся в текстах (например, такие, как ислам диненең максатлары ‘цели, стоящие перед исламом’).
5. Как нас цитировать
При использовании корпуса просим сослаться на следующие основные публикации по корпусу:
- Сулейманов Д.Ш., Невзорова О.А., Галиева А.М., Гатиатуллин А.Р., Гильмуллин Р.А., Хакимов Б.Э. Размеченный корпус татарского языка «Туган тел»: аспекты реализации // Труды Казанской школы по компьютерной и когнитивной лингвистике TEL-2014. – Казань: Изд-во «Фэн» Академии наук РТ, 2014. – С.88-93.
- Невзорова О.А., Салимов Ф.И., Хакимов Б.Э., Гатиатуллин А.Р., Гильмуллин Р.А. Галиева А.М., Якубова Д.Д. Аюпов М.М. Семантико-грамматическая аннотация в русско-татарской лексикографической базе данных // Филологические науки. Вопросы теории и практики. Тамбов: Грамота, 2012. №7 (18): в 2-х ч. Ч.1. - C.141-146.
- Невзорова О.А., Мухамедшин Д.Р., Билалов Р.Р. Корпус-менеджер для тюркских языков: основная функциональность // Труды международной конференции «Корпусная лингвистика - 2015». – СПб.: С.-Петербургский гос. университет, филологический факультет, 2015. – С. 344-350.
- Suleymanov Dz., Nevzorova O., Gatiatullin A., Gilmullin R., Khakimov B. National corpus of the Tatar language “Tugan Tel”: Grammatical Annotation and Implementation // Procedia - Social and Behavioral Sciences, 2013, vol. 95. Pp. 68-74.
- Galieva A., Khakimov B., Gatiatullin A. On the Way to the Relevant Grammatical Tagset for the Tatar National Corpus // EPiC Series in Language and Linguistics . Volume 1, 2016, CILC - 2016. 8th International Conference on Corpus Linguistics. Pp. 121–129.
- Nevzorova O., Mukhamedshin D., Galieva A., Gataullin R. Corpus management system: Semantic aspects of representation and processing of search queries // 2016 7th International Conference on Sciences of ElectronicsTechnologies of Information Telecommunications (SETIT). 2016. Pp. 285 — 290.
Более полный список публикаций авторов проекта по разработке и использованию корпуса можно найти во вкладке “ПУБЛИКАЦИИ” на главной странице корпуса.
Нужно также указать электронный адрес ресурса: Татарский национальный корпус «Туган тел». – URL: http://tugantel.tatar/.
6. Обратная связь
В случае обнаружения ошибок и при возникновении вопросов можно писать нам по адресу: tatarcorpus@gmail.com.
7. Благодарности
Проект выполняется в Институте прикладной семиотики Академии наук Республики Татарстан в рамках гранта Российского научного фонда «Разработка моделей связывания терминологии в разных языках (на материале русского и татарского языков)», проект № 16-18-02074.
8. Использованная литература
- Галиева А.М., Хакимов Б.Э., Гатиатуллин А.Р. Метаязык описания структуры татарской словоформы для корпусной грамматической аннотации // Ученые записки Казанского университета. Серия Гуманитарные науки. – 2013. – Том 155, Книга 5. – С. 287-296.
- Захаров В.П., Богданова С.Ю. Корпусная лингвистика: Учебник для студентов. – СПб.: СПбГУ, РИО Филологический факультет, 2013. – 148 с.
- Мишарский диалект татарского языка. Очерки по синтаксису и семантике / Под ред. Е.А. Лютиковой, К.И Казенина, В.Д. Сооловьева, С.Г.Татевосова. - Казань: Магариф, 2007. - 383 с.
- Национальный корпус русского языка. - URL: http://www.ruscorpora.ru/
- Невзорова О.А., Мухамедшин Д.Р., Билалов Р.Р. Корпус-менеджер для тюркских языков: основная функциональность // Труды международной конференции «Корпусная лингвистика - 2015». – СПб.: С.-Петербургский гос. университет, филологический факультет, 2015. – С. 344-350.
- Система обозначений грамматических категорий в Татарском национальном корпусе “Туган тел”. – URL: http://ips.antat.ru/datas/files/Tel2014/Annotation.docx
- Сулейманов Д.Ш., Невзорова О.А., Галиева А.М., Гатиатуллин А.Р., Гильмуллин Р.А., Хакимов Б.Э. Размеченный корпус татарского языка «Туган тел»: аспекты реализации // Труды Казанской школы по компьютерной и когнитивной лингвистике TEL-2014. – Казань: Изд-во «Фэн» Академии наук РТ, 2014. – С.88-93.
- Татарский национальный корпус «Туган тел». – URL: http://tugantel.tatar/
- Leipzig Glossing Rules. – URL: https://www.eva.mpg.de/lingua/pdf/Glossing-Rules.pdf.